Polymer Basics (all content)
Note: DoITPoMS Teaching and Learning Packages are intended to be used interactively at a computer! This print-friendly version of the TLP is provided for convenience, but does not display all the content of the TLP. For example, any video clips and answers to questions are missing. The formatting (page breaks, etc) of the printed version is unpredictable and highly dependent on your browser.
Contents
Aims
At the end of this package you should:
- Know what polymers are and understand their classification based on structure, properties and chemical composition.
- Have a basic understanding of polymer science with which you can go on and tackle more advanced areas, such as the other polymer-related TLPs detailed on the Going Further page.
Before you start
This TLP assumes no prior knowledge of polymer science. An understanding of basic chemistry principles is advantageous but not required.
Introduction
Polymers are large molecules made up of long sequences of smaller units. They occur widely in nature and synthetic polymers are a very popular manufacturing material. Polymers are relatively inexpensive to produce on a large scale, and their microstructure can be easily controlled by using different starting materials and by processing them in different ways. This leads to a very wide range of possible properties that are useful for many applications.
The basic structure of a polymer molecule is a long chain of covalently bonded atoms called the backbone. In most common synthetic polymers, the backbone is made of carbon. Attached to the backbone in a regular pattern are other atoms or groups of atoms called side groups. The simplest possible side groups are single hydrogen atoms, as in poly(ethene). The molecules that are bonded together during polymerisation to make up the polymer are called monomers. The arrangement of atoms in the monomer becomes the repeating pattern in the polymer - the repeat unit.
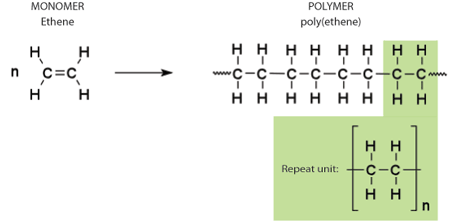
Synthetic examples
You can use the following Flash application to find out about some example synthetic polymers, and to view their monomers. Click and drag the 3D models to rotate them.
Examples of biopolymers
Polysaccharides
Polysaccharides are a type of carbohydrate produced by the polymerisation of individual sugar molecules (monosaccharides). Used as an energy store: starch for plants and glycogen for animals, or for structural support, e.g. cellulose in plants.
Polypeptides
Polypeptides are formed by the polymerisation of amino acids. One or more polypeptide molecules make up a protein. Proteins have a wide variety of functions, which include providing structure and as enzymes, which catalyse chemical reactions.
Collagen is the most abundant protein in the human body, being found in arterial walls, skin, muscle, cartilage, bone and walls of arteries. Amylase is an enzyme which catalyses the digestion of starch, which is a polysaccharide, into its constituent monosaccharides.
Naming polymers
Polymer nomenclature can be a confusing area, because several different names exist for almost every polymer. These include the chemical names (which describe the chemical structure of the molecule itself), any brand names used for marketing the material, and acronyms or abbreviations for either of these. For example, the molecule poly(tetrafluoroethene) is sold under the brand name Teflon and abbreviated to PTFE.
Another source of confusion is that there are several competing sets of rules for defining chemical names, not one single accepted system. Most of these involve writing poly followed by the monomer name in parentheses. For example, the polymer formed from the monomer tetrafluoroethene is simply poly(tetrafluoroethene).
If the structure of the monomer is different to that of the polymer it is more common to use the chemical name of the repeat unit instead of the monomer. When the repeat units become very complex, yet more systems of names are used, for example for epoxies and polyamides (nylons). For clarity we won’t deal with these here.
International differences and colloquial names add one final level of complexity – for example, C2H4 is ethene in Europe but ethylene in North America.
It is worth being familiar with the different names for some of the more common polymers, some of which you saw in the Introduction.
Shape, size & structure I
Configuration and conformation
Configuration is a property which encompasses:
- The direction (head-to-tail, head-to-head …) in which the monomers are linked together.
- The order (ABABAB…) in which monomers are joined together (in polymers with more than one type of monomer).
The configuration is fixed during synthesis.
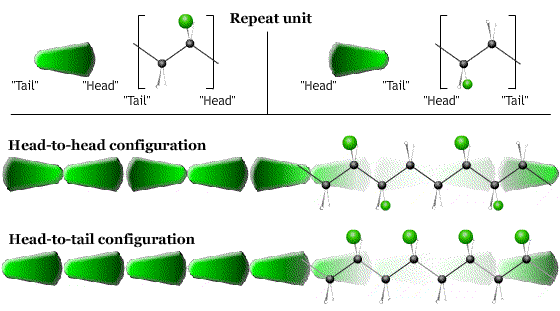
After synthesis, the molecule can change its shape by rotations about the single C-C bonds in the backbone. The particular arrangement of the chain due to these rotations is called the conformation.
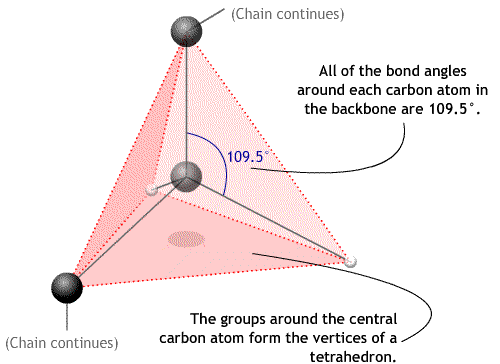
The angles between bonds around a carbon atom in the backbone are approximately 109.5°. This is the bond angle and is contant.
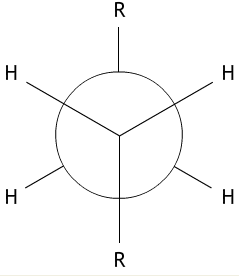
We can illustrate conformation using a Newman projection. This is a diagram which shows the arrangement of the side groups, looking down the C-C bond (represented by a circle) from one carbon atom to the other. Newman projections clearly show the torsion angle – the angle through which one carbon atom is rotated relative to the next.
There is a potential energy that comes from the interaction of side groups on adjacent carbon atoms in the chain. This energy varies as a function of the torsion angle, as side groups move relative to each other. The torsion angles with the lowest energy are more stable. These are called trans, gauche + and gauche -. The conformations that a chain will preferentially adopt are sequences of these three stable angles.
The following application is an introduction to Newman projections using the example of butane. It also illustrates the change in potential energy with torsion angle for butane.
The idea of Newman projections for butane can be extended to longer chains. In this case the CH3 groups on the diagram would be replaced by the symbol R, which stands for any group of atoms. This is shown below.
Using the following application you can build a chain of poly(ethene) with your own conformation, choosing In order to change between favourable torsion angles, the molecule must pass through those with higher energies. This represents a potential energy barrier to conformation changes.
The more energy available to a molecule, the more readily it may change its conformation, and its stiffness decreases. However, the more flexible the molecule, the more likely it is to adopt a random conformation, so the stiffness of the polymer material itself may actually increase with temperature.
Much more detail on conformation & stiffness in the context of rubber can be found in the stiffness of rubber TLP.
Below a certain temperature, the glass transition temperature Tg, a molecule’s internal energy is low enough that changes in shape of a molecule cannot be effected by conformation changes, but must instead be accommodated by stretching intermolecular bonds. The properties of a polymer change drastically below its glass transition temperature. This area is explored in the glass transition in polymers TLP.
Polymer chain morphology
A single polymer chain can exist in any one of its possible conformations, from a tight coil to a straight chain. The probability of it having a particular end-to-end distance increases with the number of possible conformations that would achieve that size. There is only one possible conformation that will produce a straight chain, but as the molecule becomes more coiled the number of possibilities increases. A polymer chain will therefore tend to coil up to some extent.
The expected end-to-end distance of a chain can be estimated using a model in which a molecule is considered as being made up of a large number n of segments. Each segment is rigid, but is freely jointed at both ends, so that it can make any angle with the next segment. A model ‘molecule’ can then be built by adding each of the successive segments at a random angle, a procedure called a random walk.
How does the random walk model compare to reality?
- By the nature of a random walk, a model molecule may overlap itself. Real polymers have a finite volume, so a molecule cannot ‘crash into’ itself or other chains.
- The random walk model does not take account of any complicating forces, such as the interaction of electrons in bulky side groups, which tend to inhibit bond rotation.
- Atoms in the polymer backbone are not freely jointed.
- As a result of these simplifications, performing a random walk where each segment is a single C-C bond gives an underestimate of the end-to-end distance, real polymer chains are stiffer than predicted by the model.
- To take account of this, random walk segments are modelled as being several C-C bonds in length.We can then use a quantity called the Kuhn length, l, to represent the average length assigned to a model segment.
- The Kuhn length varies for different polymers: it is longer for a stiffer molecule.
-
To illustrate this, here are some example Kuhn lengths (expressed as a multiple of the length of a C-C bond).
| Polymer | Kuhn length / C-C bond lengths | Notes |
| Poly(ethene) | 3.5 | PE is very flexible (due to low torsional barriers) |
| Poly(styrene) | 5 | PS has large side-groups which inhibit flexibility |
| DNA | 300 | DNA is very stiff due to its double helix structure |
Calculating the root mean square end-to-end distance of a random walk ‘molecule’
In two dimensions, we can estimate the distance from end to end of a molecule modelled by a random walk, given the Kuhn length and the number of segments. Each segment is represented by a vector, ![]()
You can now test this model using the simulation below.
Although this is a two-dimensional model, extending it to three dimensions gives the same result.
Shape, size & structure II
Individual chains can be linked together to produce a branched structure or a network.

Branching
Branches normally form because of side reactions that happen during the synthesis of a polymer. The degree of branching can be controlled to obtain different properties, for example by adding a second type of monomer chosen to promote branch formation.
Cross-links
Whereas branching involves joining the head of one chain to a point in the middle of another, cross-linking joins two chains together at some point along their length. Cross-linking in a polymer forms a network structure. A network is in fact one giant molecule because the cross-links are primary chemical bonds.

Without cross-links, van der Waals forces hold adjacent molecules together. These are weak attractions, caused by the interaction of electrons. They break easily on heating, allowing the molecules to slide past each other. Substances made from un-cross-linked polymers are therefore able to melt, and are called thermoplastics.
Cross-links are primary chemical bonds, which require much more energy to break than van der Waals forces. When a polymer of this type is heated, the covalent cross-links prevent individual molecules from sliding past one another, so melting does not occur. This type of polymer is called a thermoset. At a sufficiently high temperature, the covalent bonds both in the cross-links and within the molecules are broken, and the thermoset decomposes.
A polymer with only a small degree of cross-linking is an elastomer. The cross-links are infrequent enough to allow significant conformation changes in the chains between cross-links, while still preventing individual molecules from flowing past each other. Elastomers can accommodate a large amount of recoverable deformation, behaviour typical of rubber. Much more information about the behaviour of elastomers is available in the Stiffness of Rubber TLP.
Cross-links may be added after synthesis by a separate process. One such process is vulcanisation, where cross-links are added to rubber by heating it with sulphur.
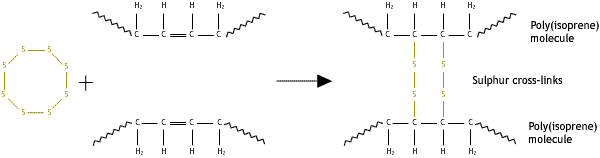
Stereoregularity
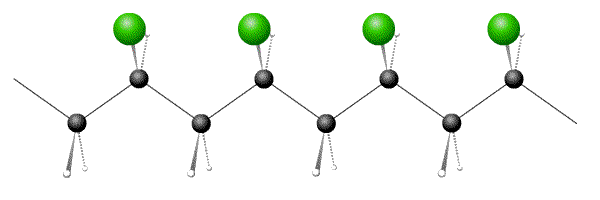
Also known as tacticity, this property describes the regularity of the side group orientations on the backbone. The tacticity of a polymer has important implications for its degree of long-range order.
The side groups of isotactic polymers all have the same orientation:
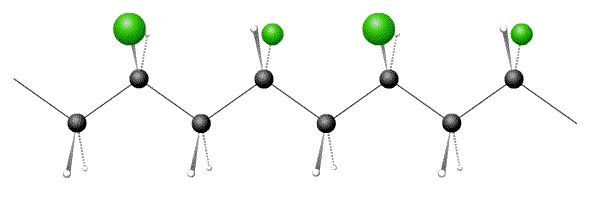
Syndiotactic polymers have alternating arrangements of side-groups:
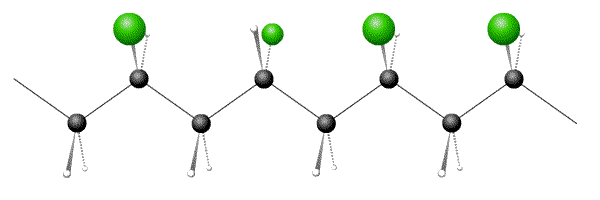
In atactic polymers the side-group orientations are random along the chain.
Copolymers
A polymer whose monomers are all identical is a homopolymer. However, polymers may be synthesised using two or more different monomers, and this produces a copolymer. This is a useful process; for example if two monomers each produce a homopolymer with a desirable property, a copolymer can be produced which combines them.
The properties of the copolymer depend on the monomers and their configuration; these may be divided into four categories: alternating, random, block and graft (illustrated below).
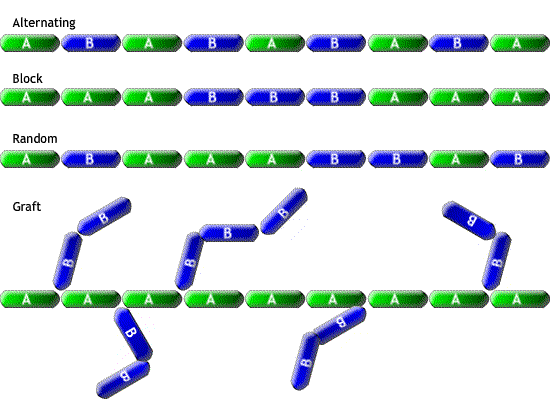
Crystallinity
Crystallinity defines the degree of long-range order in a material, and strongly affects its properties. The more crystalline a polymer, the more regularly aligned its chains. Increasing the degree of crystallinity increases hardness and density. This is illustrated in poly(ethene).
HDPE (high density poly(ethene)) is composed of linear chains with little branching. Molecules pack closely together, leading to a high degree of order. This makes it stiff and dense, and it is used for milk bottles and drainpipes.
The numerous short branches in LDPE (low density poly(ethene)) interfere with the close packing of molecules, so they cannot form an ordered structure. The lower density and stiffness make it suitable for use in films such as plastic carrier bags and food wrapping.
Often, polymers are semi-crystalline, existing somewhere on a scale between amorphous and crystalline. This usually consists of small crystalline regions (crystallites) surrounded by regions of amorphous polymer.

Factors favouring crystallinity
In general, factors causing polymers to be more ordered and regular tend to lead to a higher degree of crystallinity.
- Fewer short branches – allowing molecules to pack closely together
- Higher degree of stereoregularity - syndiotactic and isotactic polymers are more ordered than atactic polymers.
- More regular copolymer configuration – having the same effect as stereoregularity
This topic is covered in the Crystallinity in Polymers TLP.
Synthesis
The process of turning monomers into a polymer is called polymerisation. Synthesis processes are classified using two different systems: the first according to the way in which the polymers grow, and the second according to the mechanism by which the chemical reactions occur.
In the first system, synthesis processes are either chain growth or step growth:
- In chain growth polymerisation, an initiator molecule starts the reaction. Monomers are then joined onto an initiated chain. This is a fast process that produces long chains soon after the reaction begins. A chain is terminated when no more monomers are available or when the chain reacts with another chain.
- In step growth polymerisation, any monomer may react with any other, so no initiator is required. Monomers first join to form short chains (dimers, trimers…), which start to combine into longer chains once the supply of monomers begins to run out. Step growth is slower than chain growth; the process is terminated when all available monomers are used up.
In the second system, synthesis processes are either addition reactions or condensation reactions:
- The polymer is the only product of addition reactions. They often involve free radicals – chemical species having an un-paired electron.
- Condensation reactions involve the loss of a small molecule such as H2O. Because of this the polymer is not the only product of the reaction. They can result in polymers whose repeat unit does not at first sight resemble the monomer.
Chain growth polymerisation usually occurs by an addition reaction, and step growth polymerisation usually occurs by a condensation reaction. However there are several exceptions, which is why the two different systems of classification are needed.
| Polymer growth mechanism | Chain growth | Step growth | ||
| Chemical reaction mechanism | Addition reactions | |||
| Condensation reactions | ||||
The following application describes the mechanisms of the chain and step growth polymerisation.
Effect of number of functional groups
The functional groups on a monomer are those that react during synthesis to form bonds with other monomers. The number of these influences the structure of the synthesis product.
| Number of functional groups on monomer | Resulting molecule |
| One | Dimer (a molecule formed from two monomers) |
| Two | Straight chain polymer |
| Three or more | Branched or network polymer |
Molecular weight
This section should strictly be called “Polymer molecular mass”, but in polymer science it is more common to refer to molecular weight than molecular mass, so this convention will be continued here.
The molecular weight of a synthetic polymer does not have a single value, since different chains will have different lengths and different numbers of side branches. There will therefore be a distribution of molecular weights, so it is common to calculate the average molecular weight of the polymer. However, there are several different ways to define the average molecular weight, the two most common being the number average molecular weight and the weight average molecular weight. Other averages exist, such as the viscosity average molecular weight, but they will not be discussed here.
When studying a polymer, the most relevant average depends on the property being investigated: for example, some properties may be more affected by molecules with high molecular weight than those with low molecular weight, so the weight average is chosen since it highlights the presence of molecules with high molecular weight.
The average molecular weight of a polymer sample can be determined using a variety of techniques, such as gel permeation chromatography, light-scattering measurements and viscosity measurements, and the type of average that is yielded depends on the technique.
Number average molecular weight, N
The number average molecular weight is defined as the total weight of polymer divided by the total number of molecules.
Total weight \( = \sum\limits_{i = 1}^\infty {{N_i}{M_i}} \)
where Ni is the number of molecules with weight Mi
Total number \( = \sum\limits_{i = 1}^\infty {{N_i}} \)
The number average molecular weight is therefore given by:
$$\overline {{M_N}} = {{\sum\limits_{i = 1}^\infty {{N_i}{M_i}} } \over {\sum\limits_{i = 1}^\infty {{N_i}} }}$$
This can also be written as:
$$\overline {{M_N}} = \sum\limits_{i = 1}^\infty {{x_i}{M_i}} $$
where xi is the number fraction (or mole fraction) of polymer with molecular weight Mi.
Weight average molecular weight, w
The weight average molecular weight depends not only on the number of molecules present, but also on the weight of each molecule. To calculate this, Ni is replaced with NiMi.
$$\overline {{M_W}} = {{\sum\limits_{i = 1}^\infty {{N_i}M_i^2} } \over {\sum\limits_{i = 1}^\infty {{N_i}{M_i}} }}$$
This can also be written as:
$$\overline {{M_W}} = \sum\limits_{i = 1}^\infty {{w_i}{M_i}} $$
where wi is the weight fraction of polymer with molecular weight Mi.
The weight average molecular weight is therefore weighted according to weight fractions.
Polydispersity Index
The polydispersity index is defined as the ratio of the weight average molecular weight to the number average molecular weight, and it gives a measure of the distribution of the molecular weight within a sample. It has a value greater than or equal to one: it is equal to one only if all the molecules have the same weight (i.e. if it is monodisperse), and the further away it is, the larger the spread of molecular weights.
Polydispersity index \( = {\raise0.7ex\hbox{${\overline {{M_W}} }$} \!\mathord{\left/
{\vphantom {{\overline {{M_W}} } {\overline {{M_N}} }}}\right.\kern-0em}
\!\lower0.7ex\hbox{${\overline {{M_N}} }$}}\)
Molecular weight distributions
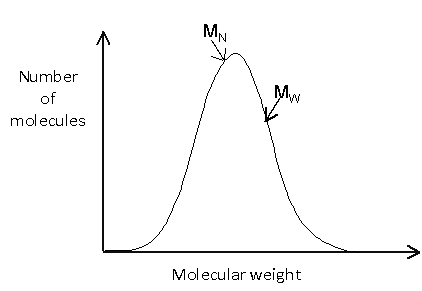
The molecular weight distribution can be shown graphically by plotting the number of molecules against the molecular weight. It is worth noting that these plots are sometimes shown with molecular weight decreasing along the x-axis.
The distribution may be relatively simple, such as:
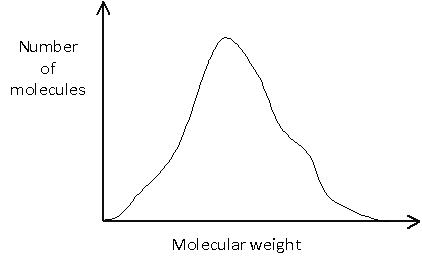
Or it may be more complicated, such as:
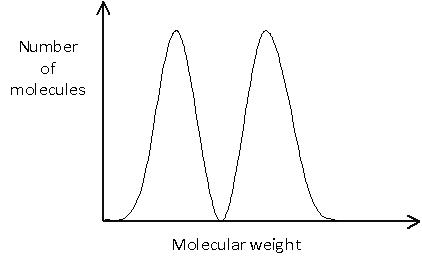
In many cases, it is important to know not only the average molecular weight, but also the distribution of molecular weights. This is illustrated in the example below, in which no molecules would actually have a weight equal to the number average molecular weight, since this would lie between the two peaks.
Polymer identification
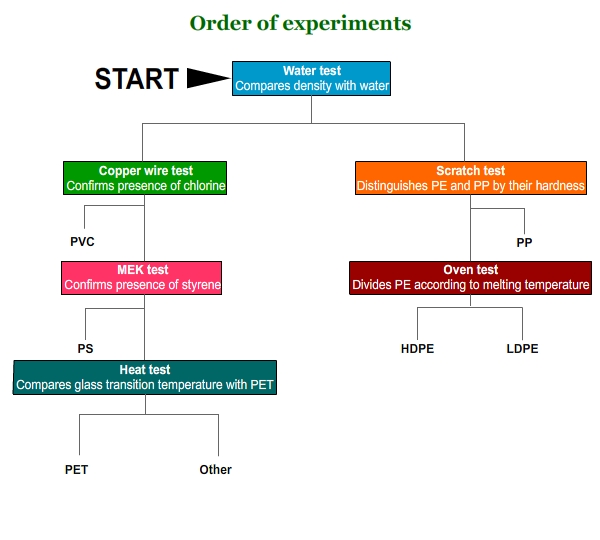
This chart gives the overall plan of action for the following activity
Summary
Polymers can be synthesised artificially from one or more type of monomers by chain growth or step growth polymerisation, or found in nature. Their names usually involve the name of the monomer(s) from which they were made.
A polymer has a fixed configuration, but may change its shape by conformation changes – rotations around C-C bonds. The polymer may be modelled as a freely jointed chain of segments, each measuring one Kuhn length. The root-mean end-to-end distance of a random walk is given by ln½.
Physical properties depend on structure:
- light cross-linking produces an elastomer,
- heavy cross-linking a thermoset and
- no cross-links a thermoplastic.
Properties also depend on crystallinity. The degree of crystallinity is controlled by the regularity of its structure, for example stereoregularity (isotactic, syndiotactic or atactic) and the amount of branching.
Synthesis produces a distribution of molecular weights, which have a number average and a weight average. Identification tests can be carried out with freely available materials.
These are the basics of polymer science and will allow you to move on to other polymer TLPs.
Questions
Quick questions
You should be able to answer these questions without too much difficulty after studying this TLP. If not, then you should go through it again!
-
Below are pictures of 3 polymers, one each of atactic, syndiotactic and isotactic. Which option has the correct sequence?
-
Which of the following polymers would be likely to have the highest crystallinity:
Deeper questions
The following questions require some thought and reaching the answer may require you to think beyond the contents of this TLP.
-
Kuhn length calculations
a) A polyethylene chain is formed from 3000 ethene monomers. Given that the length of a single carbon-carbon bond is 0.154 nm, calculate the expected end-to-end distance using the random walk model, assuming that each bond is freely jointed.
b) Given that the Kuhn length of polyethylene is equal to 3.5 C-C bond lengths, calculate an improved estimate of the expected end-to-end distance of the polymer chain. -
A polymer sample was found to have the following molecular weight distribution:
Number of moleculesMolecular weight / g/mol2005,00030010,00040020,00010040,000
Calculate the number average and weight average molecular weights, and the polydispersity index.
Going further
The following DoITPoMS TLPs cover more advanced topics relating to polymers and will provide lots of further reading. They are listed in an approximate decreasing order of relevance.
The Glass Transition in Polymers
Introduction to photoelasticity
Elasticity in biological materials
Academic consultant: Jessica Gwynne (University of Cambridge)
Content development: Andrew Wilson
Photography and video:
Web development: Lianne Sallows and David Brook
This DoITPoMS TLP was funded by the UK Centre for Materials Education and the Department of Materials Science and Metallurgy, University of Cambridge.